Hi! I am a second year PhD student in the Willow team at Inria and École Normale Supérieure in Paris, advised by Cordelia Schmid and Shizhe Chen. I am working on Diffusion models for vision-language generation.
I did my Masters by Research in Computer Science from CVIT IIIT Hyderabad advised by C.V. Jawahar and Makarand Tapaswi. My thesis was on Situation Recognition for Holistic Video Understanding, exploring structured representations to enable deeper semantic understanding of dynamic scenes. Prior to this I was a Research Assistant in the Computer Vision lab at IIT Gandhinagar, where I worked with Shanmuganathan Raman. My work centered around Computational Photography, specifically in high dynamic range (HDR) image and video reconstruction.
I am broadly interested in unified large multimodal diffusion models particularly at the intersection of vision and language for joint understanding and generation across text, images, and videos. Currently I am exploring compositional representations for high fidelity and interpretable text-to-image/video diffusion models.
CV / Google Scholar / Github / LinkedIn /
News
May, 2025 : Released our new work ComposeAnything, for compositional text to image gneration.
February, 2025 : One Paper accepted to CVPR 2025!. We create a challenging benchmark for compositional video understanding.
February, 2024 : One Paper accepted to CVPR 2024!. We design a new framework for Identity aware captioning of movie videos, we also propose a new captioning metric called iSPICE, that is sensitive to wrong identiities in captions.
September, 2023 : Started PhD in the Willow team of Inria Paris.
September, 2022 : One paper accepted to NeurIPS 2022! We formulate a new structured framework for dense video understanding and propose a Transformer based model, VideoWhisperer that operates on a group of clips and jointly predicts all the salient actions, Semantic roles via captioning and, spatio temporal grounding in a weakly supervised setting.
See all news

zeeshan.khan@inria.fr
Office: C-412
Address: 2 Rue Simone IFF, 75012 Paris France
Publications

ComposeAnything framework enables interpretable text-to-image generation for complex compositions involving surreal 2D, 3D spatial relationships and high object counts.
Zeeshan Khan, Shizhe Chen, Cordelia Schmid
under review
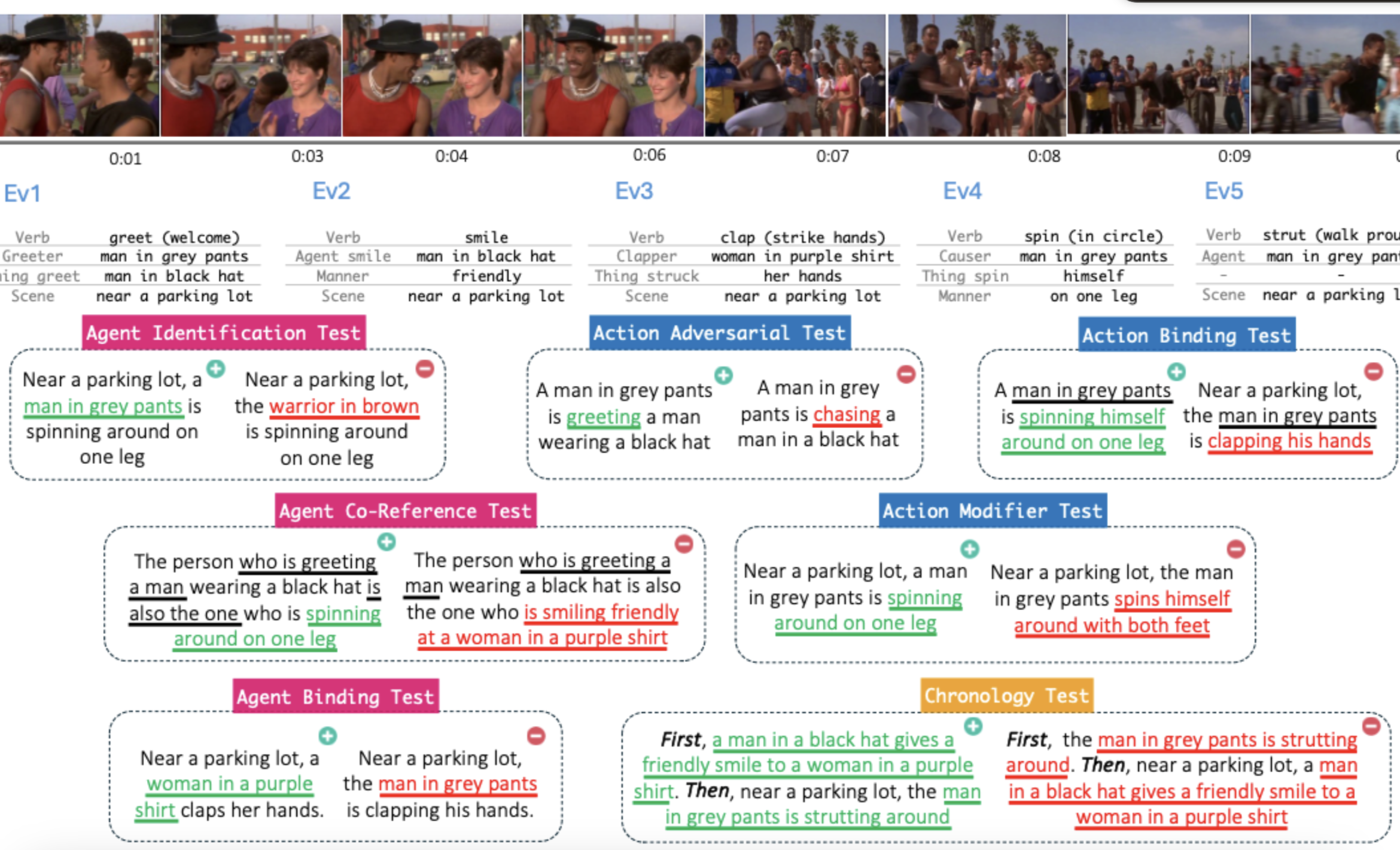
We create a new benchmark to evaluate video VLMs both contrastive and LLM based. The tasks are designed to evaluate fine-grained compositional understanding abilities of VLMs. All of the open-source VLMs perform close to random. Gemini outperforms all but with a significant gap to human performance.
Darshana Saravanan, Darshan Singh, Varun Gupta, Zeeshan Khan, Vineet Gandhi, Makarand Tapaswi,
In the Conference on Computer Vision and Pattern Recognition (CVPR) 2025
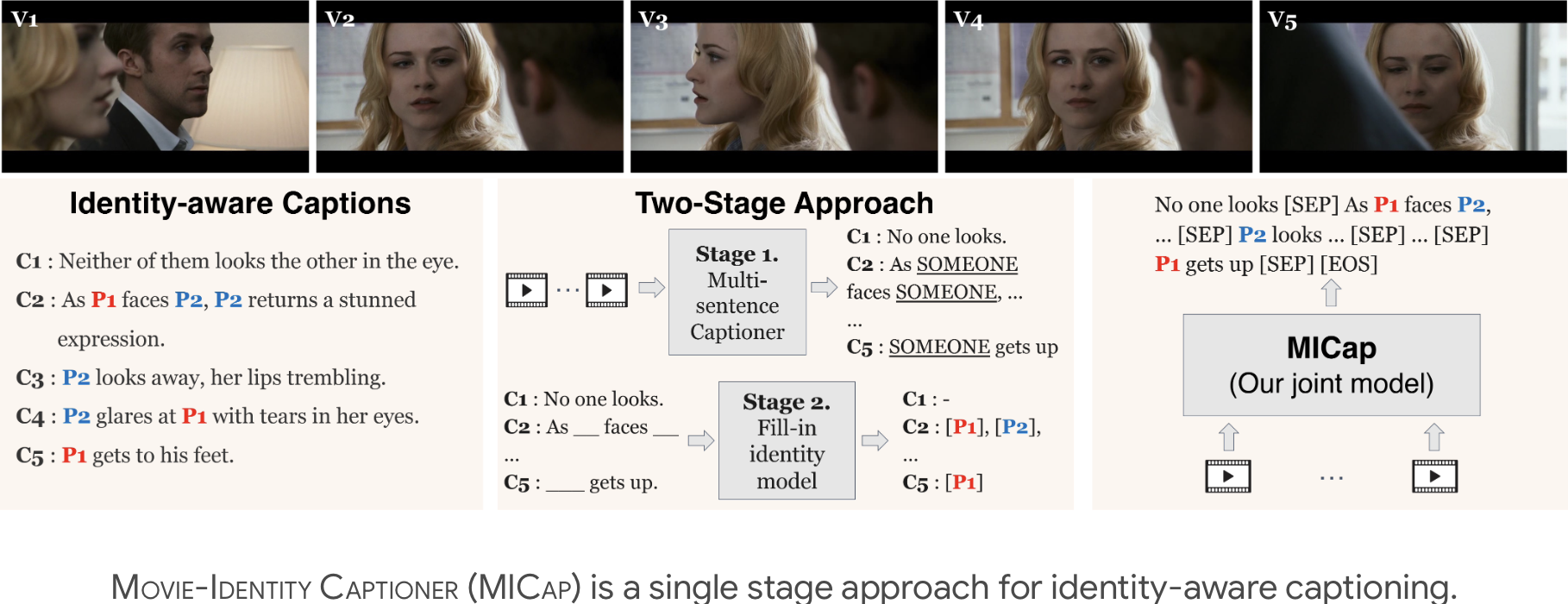
We design a single stage framework for Identity aware captioning of movie videos, we also propose a new captioning metric called iSPICE, that is sensitive to wrong identiities in captions.
Haran Raajesh, Naveen Reddy Desanur, Zeeshan Khan, Makarand Tapaswi,
In the Conference on Computer Vision and Pattern Recognition (CVPR) 2024

We formulate a new structured framework for dense video understanding and propose a Transformer based model, VideoWhisperer that operates on a group of clips and jointly predicts all the salient actions, Semantic roles via captioning and, spatio temporal grounding in a weakly supervised setting
Zeeshan Khan, C.V. Jawahar, Makarand Tapaswi
In Neural Information Processing Systems (NeurIPS), 2022

We propose to recursively prune and retrain a Transformer to find language dependent submodules that involves 2 type of paramteres, 1)Shared multlingual and 2)Unique Language dependent parameters, to overcome negative interference in Multilingual Neural Machine translation.
Zeeshan Khan, Kartheek Akella, Vinay Namboodiri, and C.V. Jawahar
In Association For Computational Linguistics (ACL) (Findings), 2021

This is the first attempt towards generating high speed high dynamic range videos from low speed low dynamic range videos. We use video frame interpolation to recursivrly generate the high and low exposure images missing in the input alternative exposure frames. The High and Low exposure frames are merged at each timestep to generate an HDR video.
Zeeshan Khan, Parth Shettiwar, Mukul Khanna, Shanmuganathan Raman
In International Conference on Pattern Recognition(ICPR), 2022 (ORAL)
![]()
We present a robut deep architecture for Appearance Consistent person image generation in novel poses. We incorporate a 3 stream network, for image, pose, and appearance. Additionaly we use Gated convolutions and, Non-local attention blocks for generating realistic images.
Ashish Tiwari, Zeeshan Khan, Shanmuganathan Raman
In International Conference on Pattern Recognition (ICPR), 2022
![]()
We address the task of improving pair-wise machine translation for low resource Indian languages using a filtered back-translation process and subsequent fine-tuning on the limited pair-wise language corpora
Kartheek Akella, Sai Himal Allu, Sridhar Suresh Ragupathi, Aman Singhal,Zeeshan Khan, Vinay Namboodiri, and C.V. Jawahar
In International Conference on Natural Language Processing(ICON) 2020
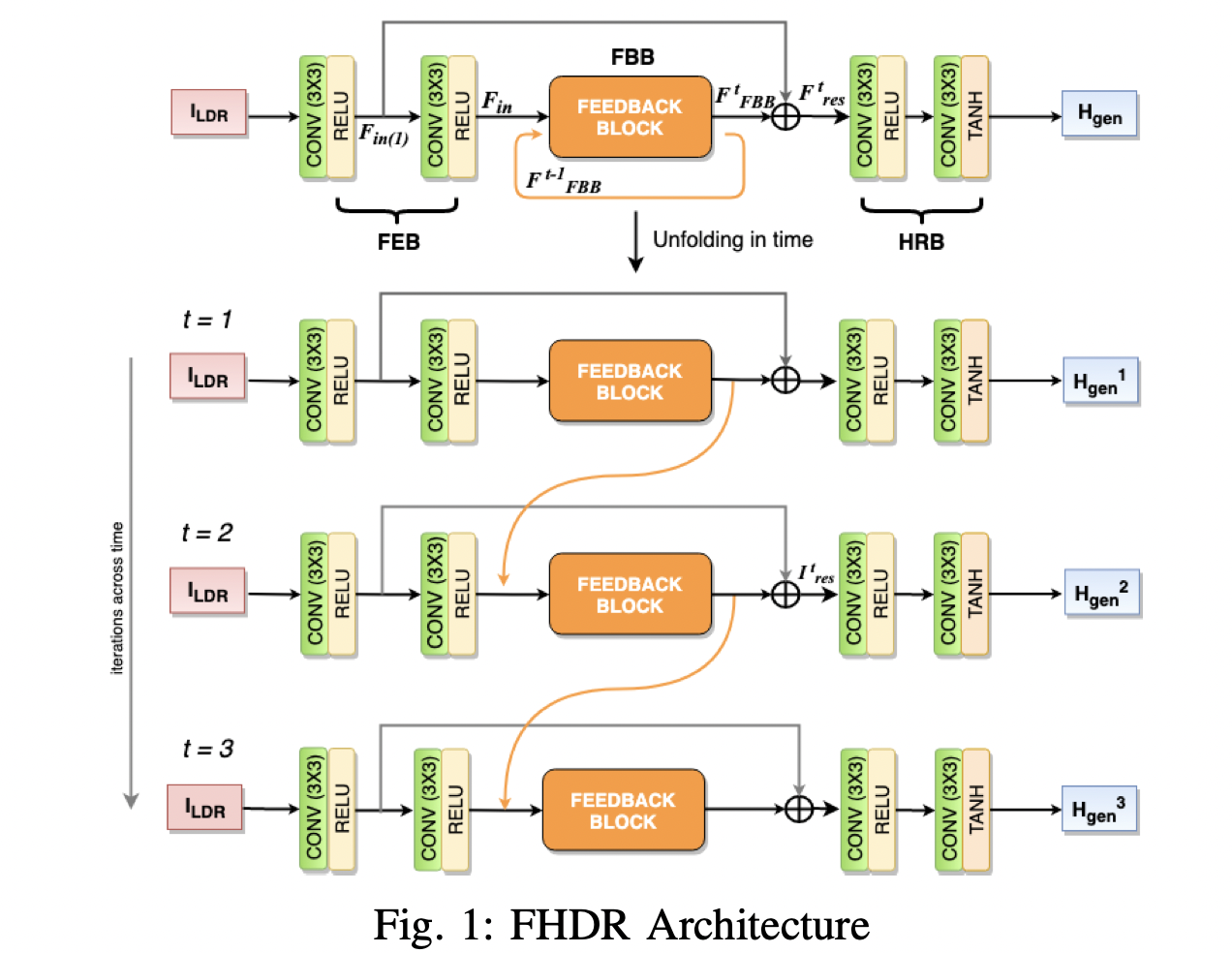
Proposed a recurrent Feedback CNN for HDR image reconstruction from a single exposure LDR image, achieving SOTA results on all the HDR benchmarks. Designed a novel Dense Feedback Block using hidden states of RNN, to transfer the high-level information to the low-level features. LDR to HDR representations are learned in multiple iterations via feedback loops.
Zeeshan Khan, Mukul khanna, and Prof. Shanmuganathan Raman
In Global Conference on Signal and Information Processing (GlobalSIP) 2019 (ORAL)