ComposeAnything: Composite Object Priors for Text-to-Image Generation
|
|
|
|
|
|
|
|

Abstract
Generating images from text involving complex and novel object arrangements remains a significant challenge for current text-to-image (T2I) models. Although prior layout-based methods improve object arrangements using spatial constraints with 2D layouts, they often struggle to capture 3D positioning and sacrifice quality and coherence. In this work, we introduce ComposeAnything, a novel framework for improving compositional image generation without retraining existing T2I models. Our approach first leverages the chain-of-thought reasoning abilities of LLMs to produce 2.5D semantic layouts from text, consisting of 2D object bounding boxes enriched with depth information and detailed captions. Based on this layout, we generate a spatial and depth aware coarse composite of objects that captures the intended composition, serving as a strong and interpretable prior that replaces stochastic noise initialization in diffusion-based T2I models. This prior guides the denoising process through object prior reinforcement and spatial-controlled denoising, enabling seamless generation of compositional objects and coherent backgrounds, while allowing refinement of inaccurate priors. ComposeAnything outperforms state-of-the-art methods on the T2I-CompBench and NSR-1K benchmarks for prompts with 2D/3D spatial arrangements, high object counts, and surreal compositions. Human evaluations further demonstrate that our model generates high-quality images with compositions that faithfully reflect the text.
Method
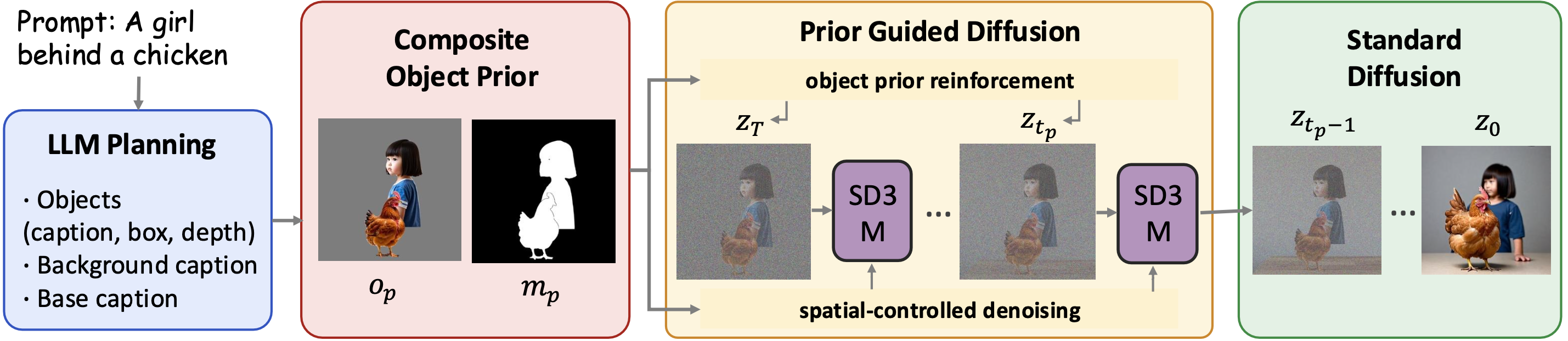
Our approach. ComposeAnything framework consists of four key components for compositional text-to-image generation: (a) LLM Planning: We employ LLMs to transform the input prompt into a structured 2.5D semantic layout, including object captions, bounding boxes and relative depths; (b) Composite Object Prior: Based on the layout, we generate a coarse composite image that serves as a strong apperance, semantic and, spatial prior, for guiding image generation; and (c) Prior Guided Diffusion: During generation we, replace random noise initialise with a noisy object prior, and iteratively reinforce the object prior. We also apply spatially-controlled self-attention to preserve semantics and structure in early denoising steps. (d) Standard Diffusion: After a few steps when the global structure if formed, we remove all the control and use standard denoising.
SOTA Comparison
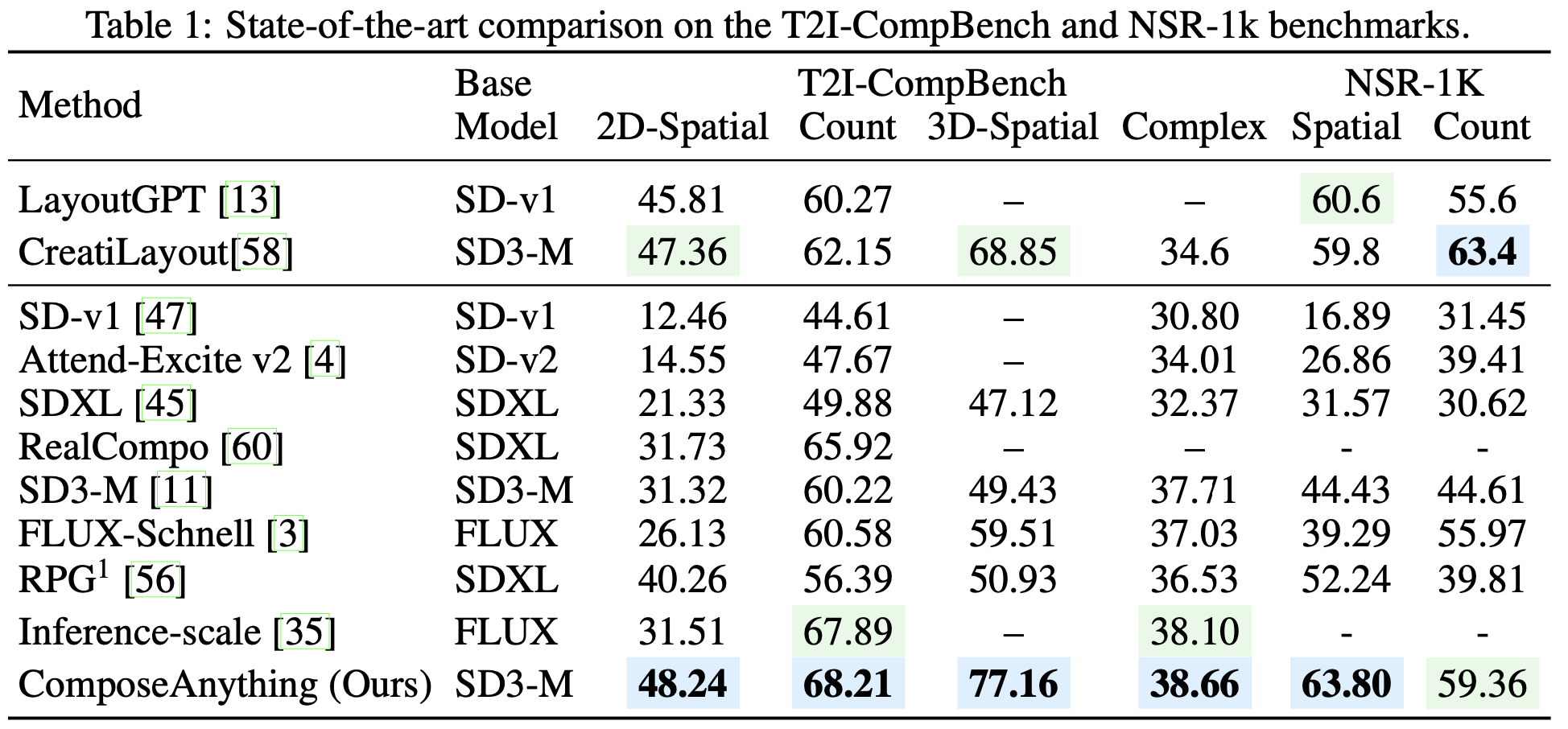
State-of-the-art Comparison. We compoare our method with both (a) training based box-conditioned models (LayoutGPT and CreatiLayout), and (b) Inference only T2I Diffusion models, including standard base models like SDXL, SD3-M, FLUX, layout based models (RealCompo and RPG) and Noise search method (Inference time scaling). Our approch outperform all the existing methods, both training-based and training-free.
Qualitative Results

Qualitative Comparison. Qualitative results of the proposed model on complex surreal prompts from T2I-Compbench. The ComposeAnything framework enables text-to-image generation for complex compositions involving surreal spatial relationships and high object counts. It enhances both visual quality and faithfulness to the input text compared to diffusion-based models (e.g., SD3, FLUX) and 2D layout conditioned models (RPG and CreatiLayout).
Composite Object Prior and Generated Image

Qualitative performance. Qualitative results of the proposed model on T2I-Compbench- We show the input prompt, the LLM generated composite object prior, and the corresponding generated image.
BibTeX
@inproceedings{khan2025composeanything,
title={ComposeAnything: Composite Object Priors for Text-to-Image Generation},
author={Zeeshan Khan and Shizhe Chen and Cordelia Schmid},
year={2025},
eprint={2505.24086},
archivePrefix={arXiv},
url={https://arxiv.org/abs/2505.24086},
}
Acknowledgements
This work was granted access to the HPC resources of IDRIS under the allocation AD011014688R1 made by GENCI. It was funded in part by the French government under management of Agence Nationale de la Recherche as part of the “France 2030" program, reference ANR-23-IACL-0008 (PR[AI]RIE-PSAI projet), and Paris Île-de-France Région in the frame of the DIM AI4IDF. Cordelia Schmid would like to acknowledge the support by the Körber European Science Prize.
Copyright
The documents contained in these directories are included by the contributing authors as a means to ensure timely dissemination of scholarly and technical work on a non-commercial basis. Copyright and all rights therein are maintained by the authors or by other copyright holders, notwithstanding that they have offered their works here electronically. It is understood that all persons copying this information will adhere to the terms and constraints invoked by each author's copyright.